Design a Rate Limiter
Who Asks This Question?
The rate limiter is a favorite at companies that operate large-scale APIs. Based on interview reports, it's frequently asked at:
- Stripe — Their entire business is API-first; they use token bucket for API throttling
- Cloudflare — They process millions of requests per second and built their own rate limiter
- Uber — Multiple Glassdoor reports confirm this as a system design round question
- Amazon — AWS API Gateway rate limiting is a core service
- Atlassian — Reported as a code design question with per-customer limits
- Reddit — Asked candidates to design multi-API rate limiters with per-user quotas
- Google — Appears in both system design and infrastructure-focused interviews
This question tests whether you've dealt with production traffic problems. Companies that ask it want to see that you understand the gap between "counting requests" (easy) and "counting requests across 50 servers without adding latency" (hard).
What the Interviewer Is Really Testing
Most candidates treat this as an algorithm problem: "Which counting algorithm should I pick?" That's only 20% of what interviewers evaluate. Here's the actual scoring breakdown at most companies:
| Evaluation Area | Weight | What They're Looking For |
|---|---|---|
| Requirements gathering | 15% | Do you ask the right questions, or do you start drawing boxes? |
| Algorithm knowledge | 20% | Can you explain trade-offs, not just recite names? |
| System architecture | 25% | Where does this component live? How does data flow? |
| Distributed challenges | 25% | Race conditions, consistency, multi-region — this is where seniors shine |
| Production awareness | 15% | Monitoring, failure modes, graceful degradation |
The #1 reason candidates fail this question: they spend 15 minutes explaining token bucket mechanics while the interviewer waits for them to mention literally anything about distributed systems. The algorithm is table stakes — the distributed part is the interview.
Step 1: Clarify Requirements
Questions You Must Ask
Don't just nod and start designing. These questions change your architecture fundamentally:
"Is this client-side or server-side rate limiting?" Always server-side. Client-side limits are trivially bypassed. But asking this shows you know the difference.
"What's the throttle key — user ID, IP, API key, or something else?" This determines your counter storage design. User ID requires authentication first. IP is simpler but problematic with NAT and VPNs (thousands of users sharing one IP). API key is the cleanest for B2B APIs.
"Single data center or globally distributed?" This is the most important question. A single-server rate limiter is a 10-minute problem. A globally distributed one is a 35-minute discussion. Most interviewers want distributed.
"What happens when the rate limiter itself fails?" This reveals your production mindset. Two valid answers:
- Fail open: Allow all traffic through (risk: no protection during outage)
- Fail closed: Block all traffic (risk: complete service disruption)
Most production systems fail open because a rate limiter outage shouldn't become a full service outage.
Requirements You Should State
After asking questions, explicitly state what you're building:
Functional:
- Limit requests based on configurable rules (per user, per IP, per endpoint)
- Return HTTP 429 with rate limit headers when throttled
- Support different limits for different API endpoints
Non-functional:
- Must add less than 5ms latency to each request (the rate limiter shouldn't be the bottleneck)
- Must work across a horizontally scaled server fleet
- Must degrade gracefully — if the rate limiter is down, traffic still flows
Step 2: High-Level Architecture
Where Does It Live?
There are three placement options, and your choice signals your experience level:
Inline middleware (most common answer): Every API server has rate limiter middleware that checks a shared counter store (Redis) before forwarding the request. This is what most candidates describe and it's a solid baseline.
API gateway layer (production-grade answer): In microservices architectures, the API gateway already handles auth, routing, and TLS termination. Adding rate limiting here avoids duplicating logic across every service. AWS API Gateway, Kong, and Envoy all support this natively.
Sidecar proxy (advanced answer): In service mesh architectures (Istio, Linkerd), rate limiting runs as a sidecar alongside each service. This gives per-service limiting without code changes.
A strong answer mentions at least two options and explains your choice: "I'd implement this at the API gateway layer because we already route all traffic through it, and it keeps rate limiting logic centralized rather than duplicated across services."
Architecture Components
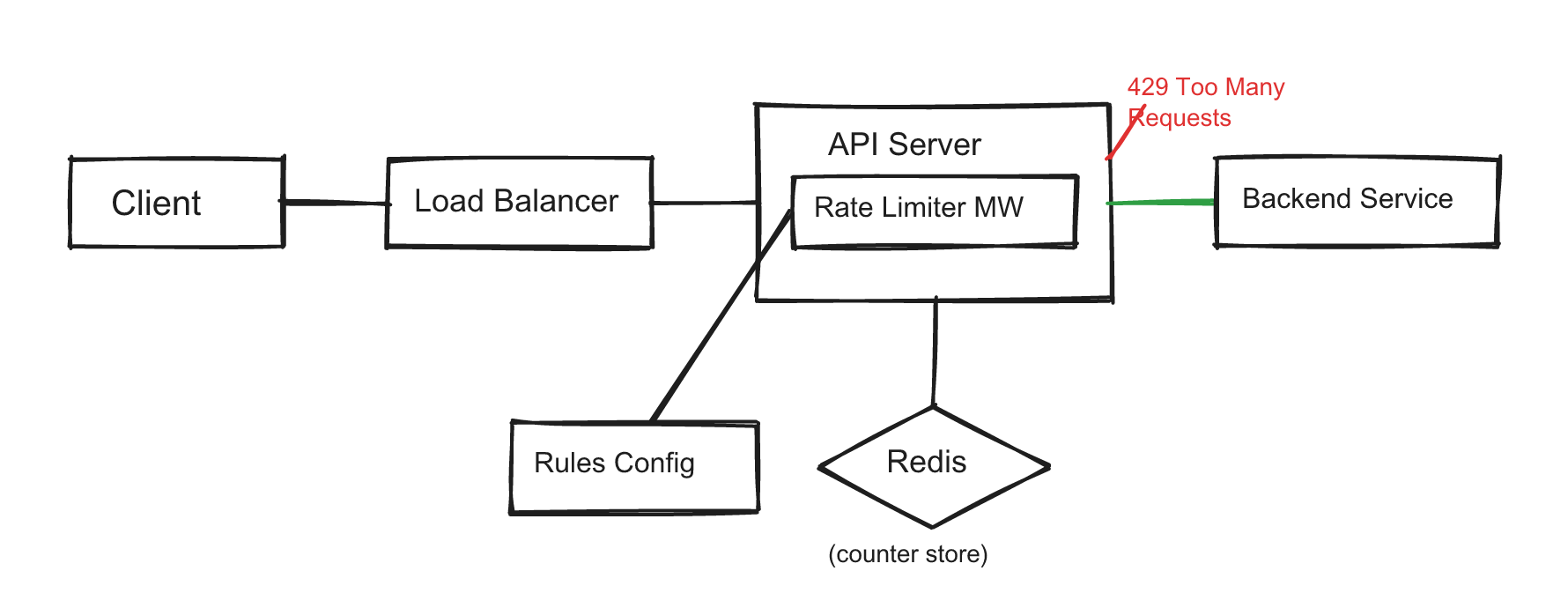
Request flow:
- Request arrives at the API server
- Rate limiter middleware extracts the throttle key (user ID, IP, etc.)
- Middleware loads the applicable rule from its in-memory cache
- Middleware checks the counter in Redis using an atomic operation
- If under limit → forward to backend, return response with rate limit headers
- If over limit → return HTTP 429 immediately, never touching the backend
Rate Limit Rules
Rules are configuration, not code. Store them in a config service or file and cache them in memory:
- endpoint: "/api/v1/messages"
key: user_id
limit: 100
window: 60 # seconds
- endpoint: "/api/v1/auth/login"
key: ip_address
limit: 5
window: 300 # 5 failed logins per 5 minutes
- endpoint: "/api/v1/search"
key: api_key
limit: 1000
window: 3600 # per hour for B2B customers
HTTP Headers
Throttled or not, always return rate limit headers. This is a detail that separates thoughtful answers from generic ones:
| Header | Purpose |
|---|---|
X-RateLimit-Limit | Maximum requests allowed in the window |
X-RateLimit-Remaining | Requests remaining before throttling |
X-RateLimit-Reset | Unix timestamp when the window resets |
Retry-After | Seconds to wait (only on 429 responses) |
Step 3: Deep Dive — Algorithms
The Five Algorithms (Know the Trade-offs, Not Just the Names)
Interviewers don't want you to recite all five algorithms. They want you to pick one and justify it, then briefly acknowledge alternatives. Here's what you need to know:
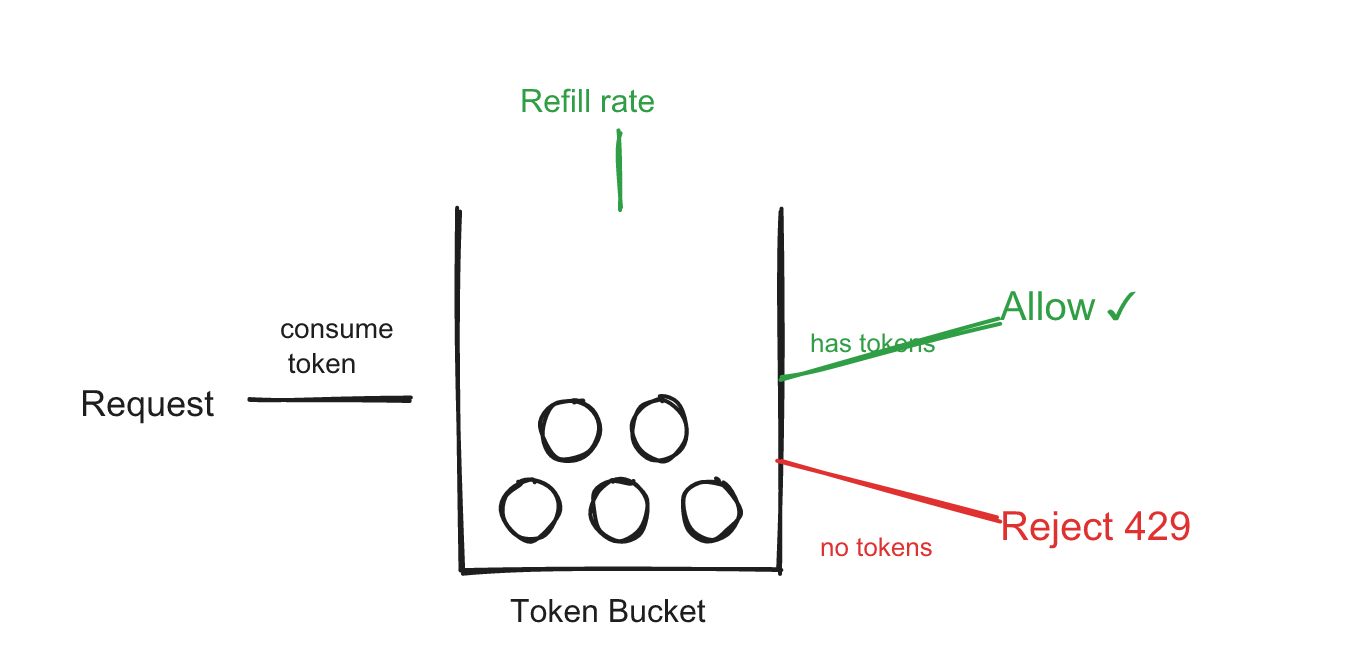
Token Bucket
Used by: Amazon (AWS), Stripe
A bucket holds tokens up to a maximum capacity. Tokens refill at a steady rate. Each request consumes one token. No tokens left? Request rejected.
Why it's popular: It naturally handles bursts. If a user was idle for a while, they've accumulated tokens and can make several quick requests. This matches real user behavior — people don't send requests at perfectly uniform intervals.
public class TokenBucket {
private final int capacity;
private final double refillRate; // tokens per second
private double tokens;
private long lastRefillNanos;
public TokenBucket(int capacity, double refillRate) {
this.capacity = capacity;
this.refillRate = refillRate;
this.tokens = capacity;
this.lastRefillNanos = System.nanoTime();
}
public synchronized boolean tryConsume() {
refill();
if (tokens >= 1) {
tokens--;
return true;
}
return false;
}
private void refill() {
long now = System.nanoTime();
double elapsed = (now - lastRefillNanos) / 1_000_000_000.0;
tokens = Math.min(capacity, tokens + elapsed * refillRate);
lastRefillNanos = now;
}
}
When to pick it: General-purpose rate limiting where you want to allow short bursts. Good default choice.
Trade-off you should state: "Token bucket allows bursts up to the bucket capacity, which is usually what we want. But if we need a perfectly smooth request rate — like feeding a downstream payment processor that can only handle exactly 10 TPS — I'd use a leaking bucket instead."
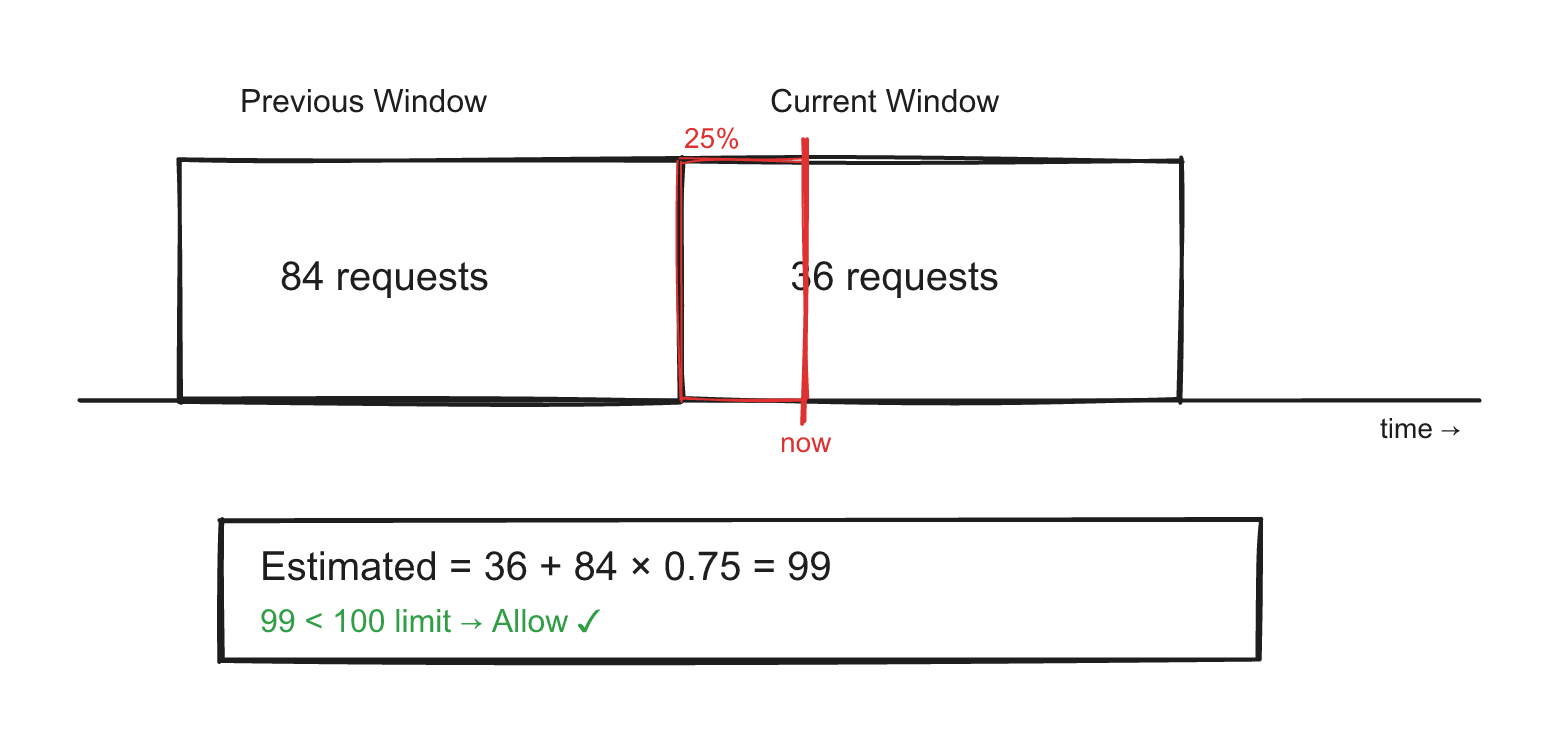
Sliding Window Counter
Used by: Cloudflare (they published a blog post about this achieving 0.003% error rate across 400 million requests)
This is the algorithm most production systems actually use because it's both memory-efficient and accurate enough. It combines two fixed windows with a weighted average:
Estimated count = currentWindowCount + previousWindowCount * overlapPercentage
Example: Limit is 100 requests/minute. Previous window had 84 requests. Current window has 36 requests. We're 25% into the current window.
Estimated = 36 + 84 * 0.75 = 36 + 63 = 99 → under limit → allow
public class SlidingWindowCounter {
private final int limit;
private final long windowMs;
private int previousCount;
private int currentCount;
private long currentWindowStart;
public SlidingWindowCounter(int limit, long windowMs) {
this.limit = limit;
this.windowMs = windowMs;
this.currentWindowStart = System.currentTimeMillis();
}
public synchronized boolean tryConsume() {
long now = System.currentTimeMillis();
if (now - currentWindowStart >= windowMs) {
previousCount = currentCount;
currentCount = 0;
currentWindowStart =
now - ((now - currentWindowStart) % windowMs);
}
double elapsed =
(now - currentWindowStart) / (double) windowMs;
double estimated =
currentCount + previousCount * (1.0 - elapsed);
if (estimated < limit) {
currentCount++;
return true;
}
return false;
}
}
When to pick it: Most production systems. Memory cost is O(1) per key — just two counters regardless of request volume. Accurate enough for virtually all use cases.
The Other Three (Know Them, Don't Lead With Them)
| Algorithm | One-Line Description | When to Mention |
|---|---|---|
| Leaking Bucket | FIFO queue that drains at a constant rate | When the interviewer asks about smooth output rate (payment processing, order queues) |
| Fixed Window Counter | Count requests in fixed time slots, reset at boundaries | Only to explain its boundary-burst problem as motivation for sliding window |
| Sliding Window Log | Store every request timestamp, count within rolling window | When the interviewer demands exact accuracy and you're OK with O(n) memory per user |
Common mistake: Walking through all five algorithms takes 15 minutes and leaves no time for the distributed design. Pick one, justify it, and move on. If the interviewer wants to hear about others, they'll ask.
Step 4: Deep Dive — Distributed Challenges
This is where strong-hire and no-hire diverge. Anyone can implement a counter on a single server. The interview is really about what happens across 50 servers in 3 data centers.
Challenge 1: Race Conditions
Two servers read the same counter from Redis, both see "count = 4" (limit is 5), both allow the request, both increment to 5. The actual count should be 6 — one request should have been rejected.
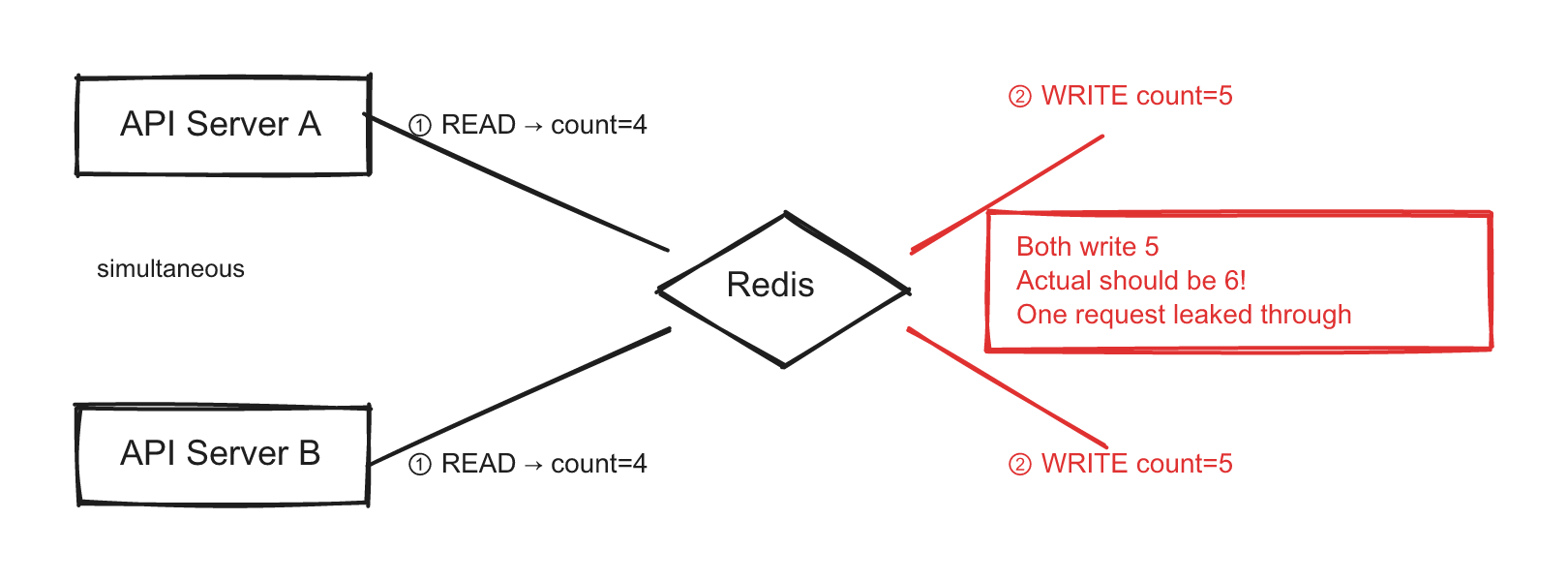
Naive approach (what weak candidates say): "Use a lock." Distributed locks add latency and create contention. At 10,000 requests/second, lock contention becomes the bottleneck.
Production approach (what strong candidates say): Use Redis's atomic INCR command. It increments and returns the new value in a single operation — no read-then-write race.
-- Redis Lua script: atomic check-and-increment
local key = KEYS[1]
local window = tonumber(ARGV[1])
local limit = tonumber(ARGV[2])
local current = redis.call('INCR', key)
if current == 1 then
redis.call('EXPIRE', key, window)
end
if current > limit then
return 0 -- rejected
end
return current -- allowed, returns remaining count
public class DistributedRateLimiter {
private final JedisPool pool;
private final String script;
public DistributedRateLimiter(JedisPool pool) {
this.pool = pool;
this.script =
"local current = redis.call('INCR', KEYS[1]) " +
"if current == 1 then " +
" redis.call('EXPIRE', KEYS[1], ARGV[1]) " +
"end " +
"if current > tonumber(ARGV[2]) then " +
" return 0 " +
"end " +
"return current";
}
public boolean allowRequest(String userId, int windowSec, int limit) {
String key = "rl:" + userId + ":" + (System.currentTimeMillis() / (windowSec * 1000));
try (Jedis jedis = pool.getResource()) {
Long result = (Long) jedis.eval(
script,
List.of(key),
List.of(String.valueOf(windowSec), String.valueOf(limit))
);
return result > 0;
}
}
}
Challenge 2: Multi-Region Consistency
Your service runs in US-East, US-West, and EU-West. Each region has its own Redis. A user sending requests to different regions could exceed their global limit because each region counts independently.
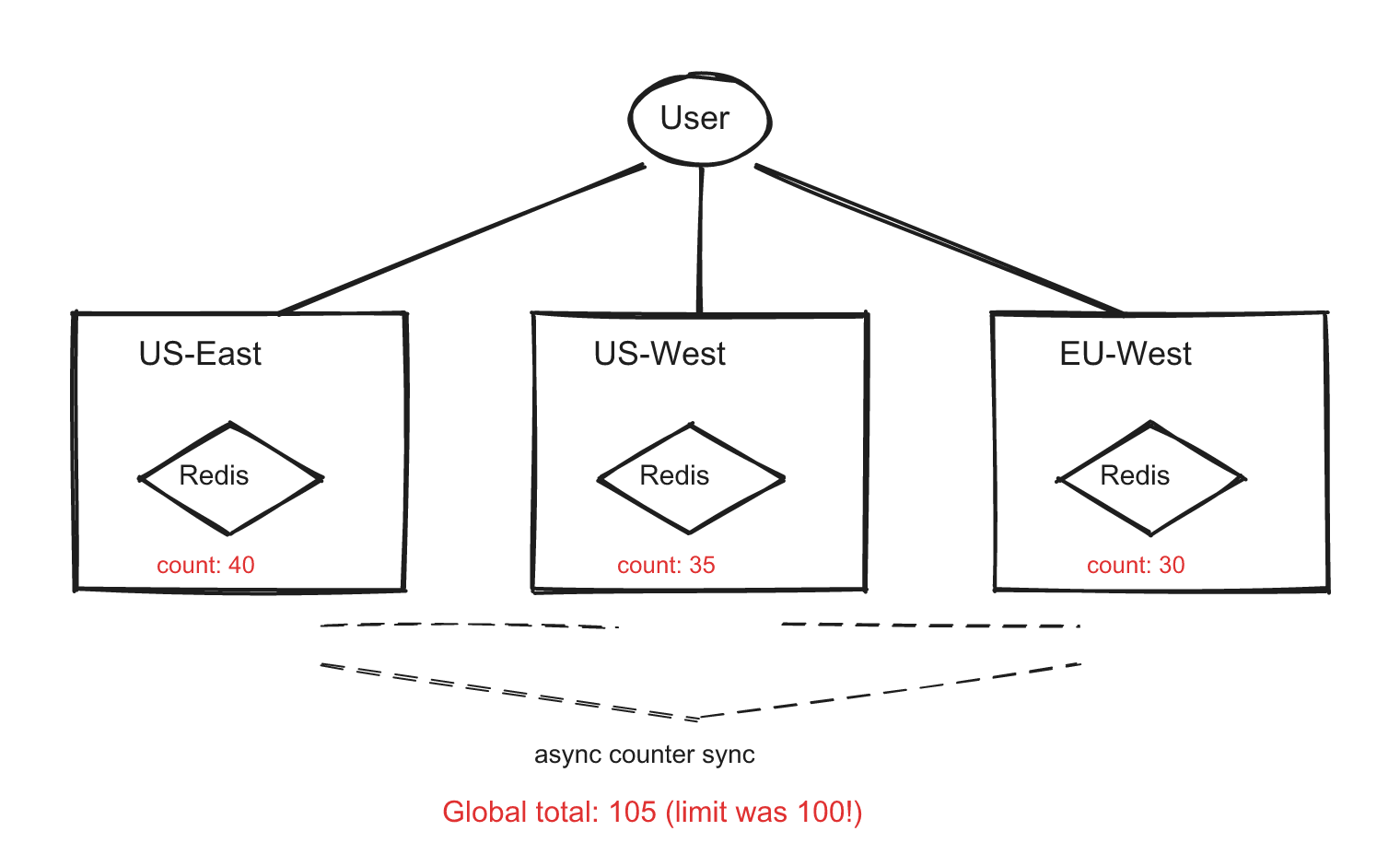
Option A: Centralized Redis (simple but slow) All regions talk to one Redis cluster. Round-trip latency from EU to US is ~100ms — unacceptable for a rate limiter that should add less than 5ms of latency.
Option B: Local Redis + async sync (fast but approximate) Each region has its own Redis. Counters sync across regions via background replication. A user's true count might be slightly behind, allowing a brief over-limit window.
Option C: Accept regional limits (pragmatic) Instead of a global limit of 100/min, give each region a proportional share: US-East gets 50, US-West gets 30, EU gets 20. No cross-region communication needed.
The strongest answer acknowledges the trade-off explicitly: "Perfect global accuracy requires cross-region latency that violates our latency budget. I'd use local counters with eventual consistency — we might briefly allow 105 requests instead of 100, but that's acceptable for rate limiting. If the interviewer needs exact global limiting, I'd use Option C with proportional regional budgets."
Challenge 3: What If Redis Goes Down?
This is the follow-up question interviewers love to ask after you mention Redis.
Weak answer: "Redis won't go down, it's highly available." Strong answer: "We need a fallback strategy."
Three fallback options:
- Fail open — Allow all traffic. The rate limiter is a safety net, not a critical path. Brief over-serving is better than a total outage.
- Local in-memory fallback — Each server maintains a local counter. Not globally accurate, but provides basic protection.
- Redis Cluster with replicas — Use Redis Sentinel or Cluster mode for automatic failover. This is infrastructure-level resilience, not application-level.
Common Mistakes
These are real patterns from interview debriefs, not hypothetical problems:
Mistake 1: Algorithm Recitation Without Justification
Describing all five algorithms without picking one shows you've memorized a textbook but can't make engineering decisions. Pick one, justify it with the requirements, and move on.
Mistake 2: Ignoring the "Where Does It Live?" Question
Jumping straight to algorithms without discussing where the rate limiter sits in the architecture. Is it middleware? API gateway? Sidecar? This decision affects everything downstream.
Mistake 3: Single-Server Design for a Distributed Question
If the interviewer said "distributed environment" and your design uses synchronized or a local HashMap, you've missed the core challenge. The single-server solution should take 2 minutes, then pivot to distributed.
Mistake 4: Over-Engineering for Small Scale
When the interviewer says "1,000 users per day," you don't need sharding, distributed caching, and multi-region sync. Scale your design to the stated requirements, then discuss what changes at higher scale.
Mistake 5: Not Mentioning Monitoring
A rate limiter without monitoring is a black box. Strong candidates mention tracking:
- How many requests are being throttled (is the limit too strict?)
- P99 latency of the rate limiter itself (is it adding too much overhead?)
- Counter store availability (is Redis healthy?)
Interviewer Follow-Up Questions
Prepare for these — they're designed to push beyond rehearsed answers:
"What if a customer complains they're being rate limited unfairly?" You need observability. Log throttle events with the customer ID, endpoint, and current counter value. Provide a dashboard where support can see a customer's recent rate limit status. Consider a "burst credit" system where long-idle customers get a temporary higher limit.
"How would you handle rate limiting for a flash sale?" Token bucket shines here — idle users have accumulated tokens and can burst. Alternatively, temporarily raise limits for specific endpoints via your config system. The key insight: rate limits should be dynamically configurable, not hardcoded.
"Should rate limiting happen before or after authentication?" Both. IP-based rate limiting should happen before auth (to protect the auth service itself from brute force). User-based rate limiting happens after auth (because you need the user identity).
"How do you rate limit WebSocket connections?" Different from HTTP. You can't return 429 on each message — the connection is already open. Options: count messages per connection per window, or use a token bucket that drains as messages are sent and refills over time.
Summary: Your 35-Minute Interview Plan
| Time | What to Do |
|---|---|
| 0-5 min | Clarify requirements: throttle key, distributed?, failure mode |
| 5-10 min | High-level architecture: placement, components, request flow |
| 10-18 min | Algorithm: pick one (sliding window counter or token bucket), justify, code the core logic |
| 18-28 min | Distributed challenges: race conditions (atomic INCR), multi-region, Redis failure |
| 28-33 min | Production: monitoring, dynamic config, HTTP headers |
| 33-35 min | Wrap up: state your trade-offs, what you'd improve |
The rate limiter interview is really a distributed systems interview in disguise. The algorithm is the easy part — showing you can reason about race conditions, consistency trade-offs, and failure modes is what gets you the offer.